Generalist robot learning remains constrained by data: large-scale, diverse, and high‐quality interaction data are expensive to collect in the real world. While simulation has become a promising way for scaling up data collection, the related tasks, including simulation task design, task-aware scene generation, expert demonstration synthesis, and sim-to-real transfer, still demand substantial human effort.
We present AnyTask, an automated framework that pairs massively parallel GPU simulation with foundation models to design diverse manipulation tasks and synthesize robot data. We introduce three AnyTask agents for generating expert demonstrations aiming to solve as many tasks as possible:
- ViPR: A novel task and motion planning agent with VLM-in-the-loop Parallel Refinement.
- ViPR-Eureka: A reinforcement learning agent with generated dense rewards and LLM-guided contact sampling.
- ViPR-RL: A hybrid planning and learning approach that jointly produces high-quality demonstrations with only sparse rewards.
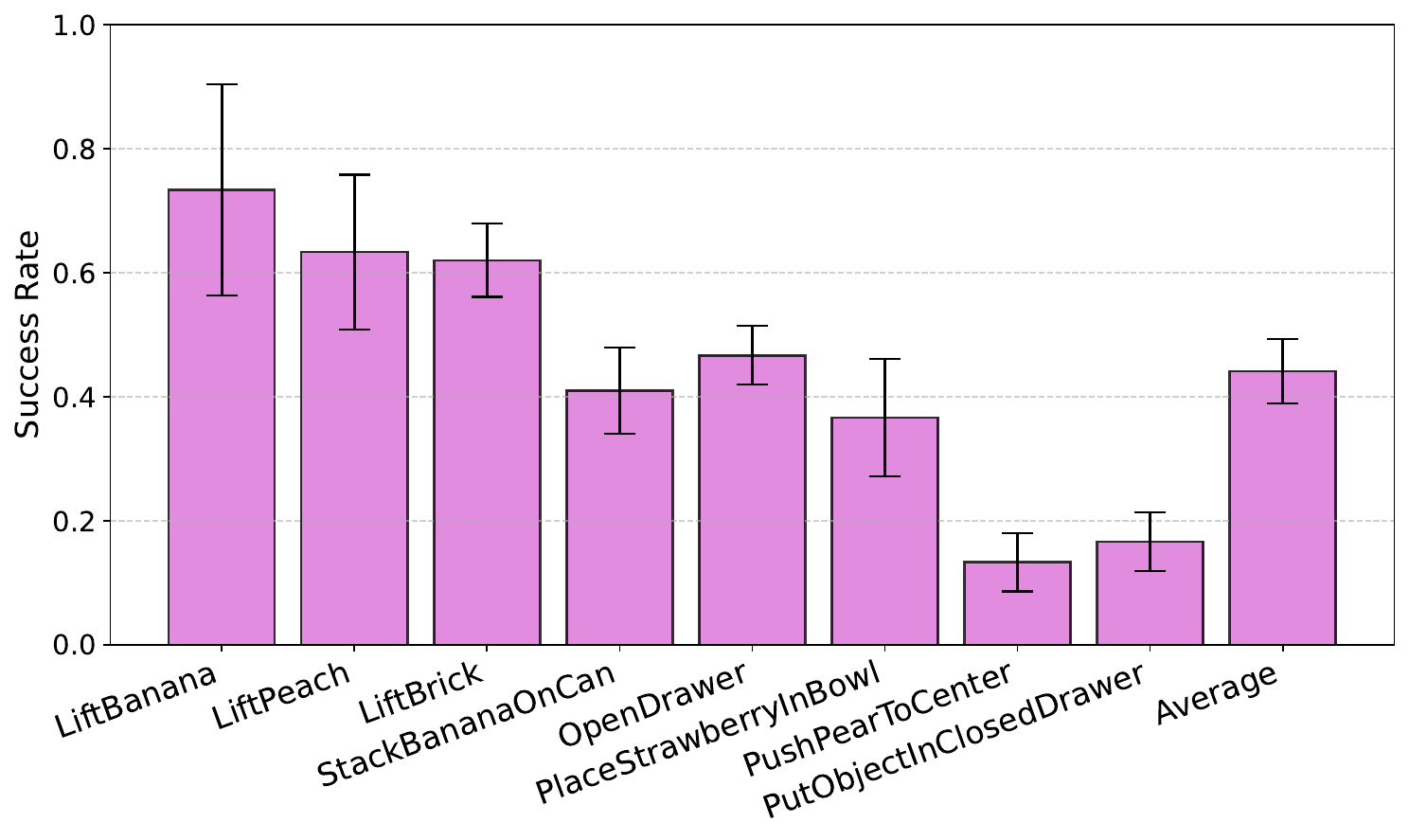
We train behavior cloning policies on generated data, validate them in simulation, and deploy them directly on real robot hardware. The policies generalize to novel object poses, achieving 44% average success across a suite of real-world pick-and-place, drawer opening, contact-rich pushing, and long-horizon manipulation tasks.
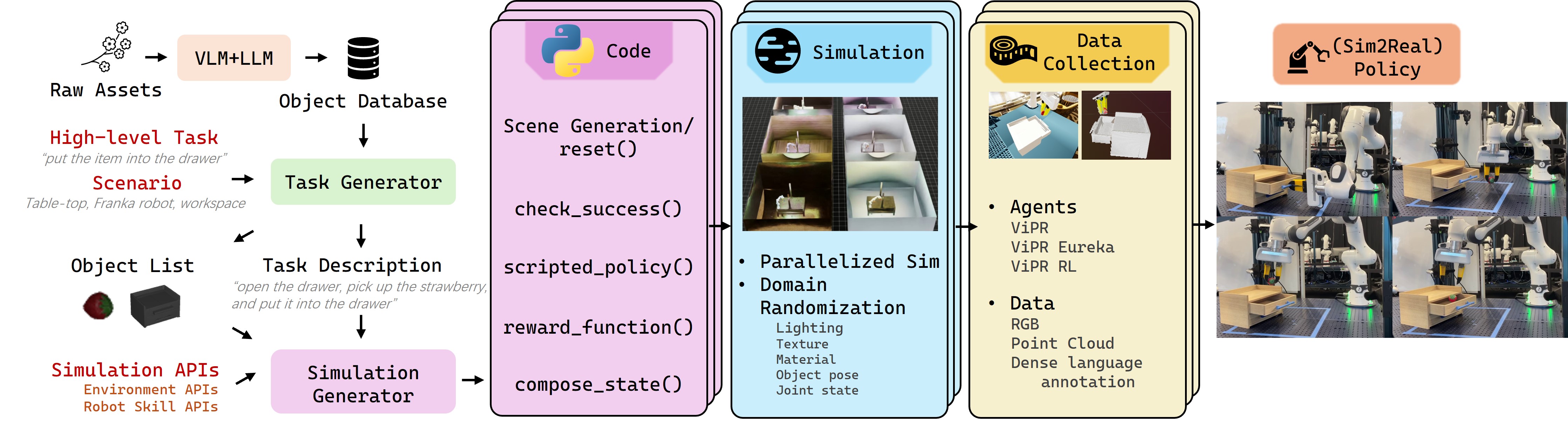
Figure 1: AnyTask System Overview. The pipeline first produces simulated manipulation tasks using an object database and high-level task types. It automatically generates task descriptions and simulation code, then efficiently collects data via ViPR, ViPR-RL, and ViPR-Eureka agents within massively parallel environments. Online domain randomization ensures diverse scenes and visual observations, allowing policies trained on this simulated data to transfer zero-shot to the real world.
Figure 2: Object Database. We generate diverse manipulation tasks using an object database.
1. ViPR Agent: A novel task and motion planning agent with VLM-in-the-loop Parallel Refinement.
2. ViPR-Eureka Agent: A reinforcement learning agent with generated dense rewards and LLM-guided contact sampling.
3. ViPR-RL Agent: A hybrid planning and learning approach that jointly produces high-quality demonstrations with only sparse rewards.
Sim-to-Real Transfer: We directly deploy the policies trained in simulation to the real robot. All videos are shown at original speed (1x).
The policies generalize to novel object poses, achieving 44% average success across a suite of real-world pick-and-place, drawer opening, contact-rich pushing, and long-horizon manipulation tasks.